
A few readers have recently written to me regarding the use of Jupyter with the downloadable source for Python for Data Science for Dummies. The version of Anaconda recommended for the book, 2.1.0, doesn’t rely on Jupyter, which is why the book doesn’t mention Jupyter. The book relies on IPython Notebook, which is what you should use to obtain the best reading experience. You can obtain the proper version from the Continuum archive. However, if you choose to download the current version of Anaconda, then using Jupyter becomes a possibility; although, many of the procedures found in the book will require tweaking and the screenshots won’t match precisely.
In order to use Jupyter, you must still import the downloaded files into your repository. The source code comes in an archive file that you extract to a location on your hard drive. The archive contains a list of .ipynb (IPython Notebook) files containing the source code for this book (see the Introduction for details on downloading the source code). The following steps tell how to import these files into your repository:
- Click Upload at the top of the page. What you see depends on your browser. In most cases, you see some type of File Upload dialog box that provides access to the files on your hard drive.
- Navigate to the directory containing the files you want to import into Notebook.
- Highlight one or more files to import and click the Open (or other, similar) button to begin the upload process. You see the file added to an upload list, as shown here. The file isn’t part of the repository yet—you’ve simply selected it for upload.
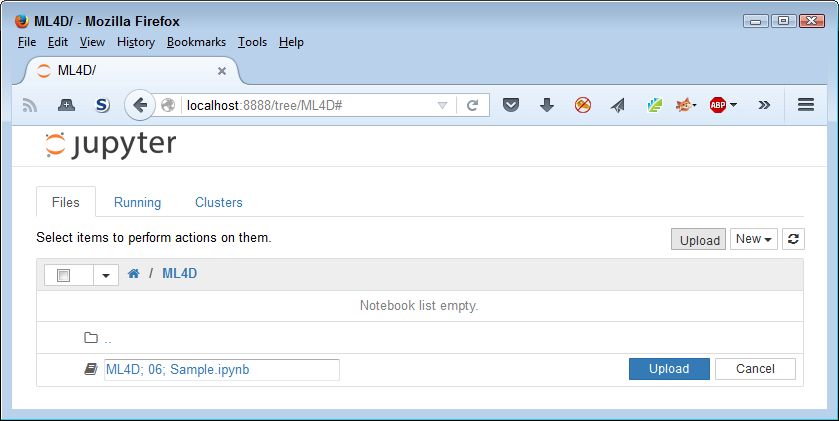
Upload Source Files to the Repository - Click Upload. Notebook places the file in the repository so that you can begin using it.
It’s important to both Luca and me that you have the best possible learning experience with our book. This means using the right version of Anaconda for most people. Using the latest version shouldn’t cause problems, but we’d like to know if it does. Please feel free contact me at [email protected] with your book-specific questions.
Update
It has come to our attention since this post first published that using the latest version of Anaconda with Python for Data Science for Dummies is problematic. Some of the examples won’t work without rewriting because the Pandas Categorical class has changed. This is the only change we’ve confirmed so far, but there are no doubt other changes. In order to get the proper results from the examples in the book, you must use the correct version of Anaconda, version 2.1.0.
Please do keep those questions coming. It’s because a reader took time to write that Luca and I became aware of this problem. We truly do want you to have a great learning experience, so these questions are important!