This is an update of a post that originally appeared on May 23, 2011.
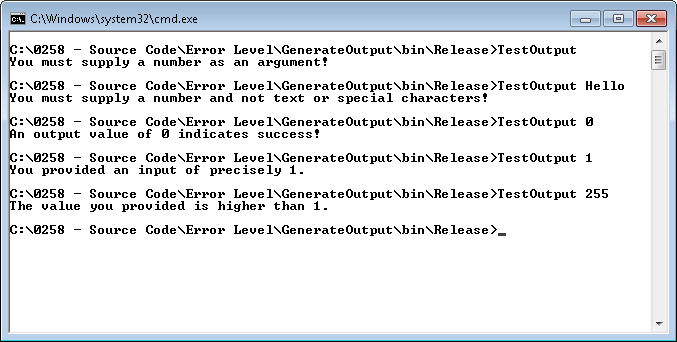
Errors in software happen. A file is missing on the hard drive or the user presses an unexpected key combination. There are errors of all shapes and sizes; expected and unexpected. The sources of errors are almost limitless. Some developers look at this vastness, become overwhelmed, and handle all errors the same way—by generating an ambiguous exception for absolutely every error that doesn’t help anyone solve anything. This is the worst case scenario that’s all too common in software today. I’ve talked with any number of people who have had to employ extreme effort just to figure the source of the exception out; many people simply give up and hope that someone has already discovered the source of the error.
At one time, error handling functionality in application development languages was so poor that it was possible to give the developer the benefit of a doubt. However, with the development tools that developers have at their disposal today, there is never a reason to provide an ambiguous “one size fits all” exception. For one thing, developers should make a distinction between the expected and the unexpected. Any expected error—a missing file for example—should be handled directly and specifically. If the application absolutely must have the file and can’t recreate it, then it should display a message saying which file is missing, where it is missing from, and possibly how to obtain another copy.
Even more than simply shoving the burden onto the user, however, modern applications have significantly more resources available for handling the error automatically. For example, it’s quite possible to use an Internet connection to access the vendor’s Web site and automatically download a missing application file. Except to tell the user what’s happening when the repair will take a few minutes, the application shouldn’t even bother the user with this particular kind of error—the repair should be automatic.
All of my essential programming books include at least mentions of error handling, debugging, exceptions, and other tasks associated with running code efficiently and smoothly. For example, Part IV of C++ All-In-One for Dummies, 4th Edition is devoted to the topic of debugging. Part V Chapter 3 of this same book talks about exceptions. If you’re a C# developer, C# 10.0 All-in-One for Dummies discusses exception handling in Book I Chapter 9. Book IV Chapter 2 discusses how to use the debugger to find errors. The point is that it’s essential to handle errors in your applications in a manner that makes sense to the users who rely on the application daily and the developers who maintain it.
Note that many of my newer books provide instructions for working with online IDEs, most especially Google Colab. These online IDEs rarely provide built-in debugging functionality, so then you need to resort to other means, such as those expressed in Debugging in Google Colab notebook.
Exceptional conditions do occur. However, even in these situations the developer must avoid the generic exception at all costs. If an application experiences an unexpected error and there isn’t any way to recover from it automatically, the user requires as much information as possible about the error in order to fix it. This means that the application should diagnose the problem as much as possible. Don’t tell the user that the application simply has to end—there is never a good reason to include this sort of message. Instead, tell the user that the application can’t locate a required resource and specify the resource in as much detail as possible. If possible, let the user fix the resource access problem and then retry access before you simply let the application die an ignoble death. Remember this! Any exception that your application displays means that you’ve failed as a developer to locate and repair the errors, so exceptions should be reserved for truly exceptional conditions.
Not everyone agrees with my approach to error trapping, but I have yet to hear a convincing argument to provide unreliable, non-specific error trapping in an application. Poor error trapping always translates into increased user dissatisfaction, increased support costs, and a reduction in profitability. Let me know your thoughts on the issue of creating a sensible error trapping strategy at [email protected].